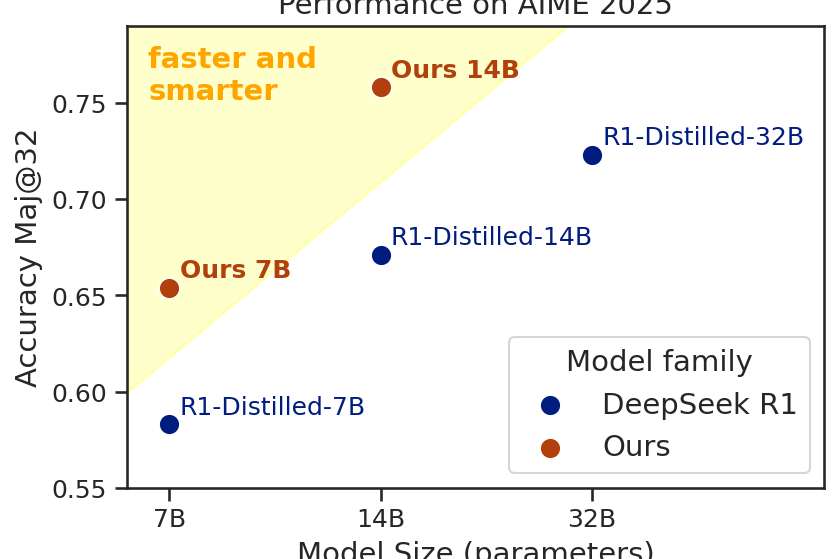
I joined a team and we trained 7B and 14B math reasoning models based on DeepSeek-R1-Distill using SFT and GRPO. Our 14B model achieved 75.8% Maj@32 on AIME’25 (+8.7% improvement), and our 7B model reached 65.8% Maj@32 (+7.5%). Here is what I’ve learned.